认识和使用 Ollama LLM 服务工具 和 openwebui
Ollama 是什么
Ollama 是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型、降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Qwen3、Llama3、Phi3、Gemma2 等开源的大型语言模型。本质上跟 docker 是同一类工具。
Ollama 相关网站
官网
Ollama 支持开源大模型仓库
github
https://github.com/ollama/ollama
官方教程
https://docs.ollama.com/quickstart
Ollama 推荐配置
虽然 Ollama 支持纯 CPU 运行,但为了获得良好体验,推荐以下最低配置:
操作系统:Ubuntu 20.04+/CentOS 7+/macOS 12+/Windows 10+
内存:至少 16GB RAM(建议 32GB)
显卡(GPU):NVIDIA GPU(CUDA 支持),显存 ≥ 8GB(如 RTX 3060/3070)
磁盘空间:预留至少 10GB 用于模型存储(GGUF 量化版更小)
若使用 NVIDIA 显卡,请确保已正确安装驱动和 CUDA Toolkit(12.x 版本兼容性最佳)。
Ollama 安装
支持 macOS、Windows、linux、Docker
macOS
Windows
Linux
curl -fsSL https://ollama.com/install.sh | sh
Docker
The official Ollama Docker image ollama/ollama is available on Docker Hub.
启动 ollama
-
客户端启动
-
打开客户端就行
-
-
命令行启动
-
ollama run qwen3-8b-test
-
ollama run qwen3-8b-test "为'用户登录'生成3条测试用例,含手机号验证码场景"
-
-
Docker 启动
-
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-
配置文件 Modelfile
当前电脑配置
GPU: RTX 3060 12GB显存
CPU: i9-10900K (10核20线程,可超频)
内存: 64GB
存储: 4TB固态硬盘
系统: Windows 10 22h2
# Modelfile
# 基础模型
FROM qwen3:8b
# 专业角色定义(核心!)
SYSTEM """
你是一名拥有10年经验的资深测试架构师,精通ISTQB标准。请严格遵循以下准则:
1. 生成测试用例时必须包含:用例ID、模块、优先级(P0-P2)、前置条件、测试步骤、预期结果、测试类型(功能/边界/异常)
2. 评审用例时重点检查:场景覆盖度、边界条件遗漏、步骤可执行性、预期结果明确性
3. 遇到模糊需求主动提问(例:"密码复杂度要求是否包含特殊字符?")
4. 输出使用标准Markdown表格,中文描述,专业术语保留英文缩写(如API/UI)
5. 保持客观严谨,避免主观表述(禁用"我觉得",改用"根据需求文档第X条")
"""
# =============== 性能参数(注释必须独立成行!) ===============
# 提升GPU负载,加速长文档解析
PARAMETER num_gpu 60
# 处理完整PRD/需求文档(实测10页PDF无压力)
PARAMETER num_ctx 16384
# 降低随机性!测试用例需高度确定性
PARAMETER temperature 0.3
PARAMETER top_p 0.85
# 严防步骤/预期结果重复
PARAMETER repeat_penalty 1.2
# 充分利用i9-10900K多核处理复杂逻辑
PARAMETER num_thread 18
Python 调用 Ollama api
Ollama api 默认端口是 11434 (如果需要其他机器调用,本地如果开了网络保护,需要单独对这个端口开放一下哦,添加一个出入站规则), win1022H2 客户端启动修改端口可通过环境变量 OLLAMA_HOST 指定绑定地址+端口(格式:<IP>:<新端口>)(注意:openwebui 对应的 ollama 端口也需要跟着修改,OLLAMA_BASE_URL=http://127.0.0.1:新端口)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: yinzhuoqun
@site: http://zhuoqun.info/
@email: yin@zhuoqun.info
@time: 2026/1/27 9:48
"""
# pip install openai
from openai import OpenAI
class OllamaQwen38B:
def __init__(self, base_url):
"""
初始化
"""
self.base_url = base_url
self.client = OpenAI(
base_url=self.base_url,
api_key=""
)
def chat(self, content):
"""
普通模式聊天输出
:param content:
:return:
"""
chat_completion = self.client.chat.completions.create(
model="qwen3:8b",
stream=False,
messages=[
{"role": "user", "content": content},
]
)
return chat_completion.choices[0].message.content
def chat_stream(self, content):
"""
流模式聊天输出
"""
chat_completion = self.client.chat.completions.create(
model="qwen3:8b",
stream=True,
messages=[
{"role": "user", "content": content},
]
)
for chunk in chat_completion:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
if __name__ == '__main__':
base_url = 'http://192.168.89.31:11434/v1/'
ai = OllamaQwen38B(base_url)
content = "深圳有什么好玩的地方?"
# 普通模式
# print("=== 普通模式 ===")
# print(ai.chat(content))
# 流模式
print("\n=== 流模式 ===")
for chunk in ai.chat_stream(content):
print(chunk, end='', flush=True)
print() # 换行
常用 Ollama 命令
日常开发中常用的 Ollama CLI 命令清单:
| 功能 | 命令 |
| 查看 ollama 版本号 | ollama --version |
| 安装指定模型 | ollama pull qwen3:8b |
| 列出已安装模型 | ollama list |
| 查看正在运行的模型 | ollama ps |
| 运行模型(交互模式) | ollama run qwen3:8b |
| 用 Modelfile 文件重建模型 | ollama create qwen3-8b-test -f Modelfile |
| 删除模型 | ollama rm qwen3:8b |
| 查看模型详细信息 | ollama show qwen3:8b --modelfile |
| 启动服务 | ollama serve |
| 推送自定义模型 | ollama push <namespace/model> |
| 所有命令均可通过 ollama --help 获取完整帮助文档或访问 https://docs.ollama.com/cli | |
导入模型或适配器(需创建 Modelfile 文件)
-
GGUF 文件
-
safetensors 文件
Ollama 服务工具 web 化
相关地址
功能介绍
https://mp.weixin.qq.com/s/osXsD9qvQp_GFu7DOAqZNA
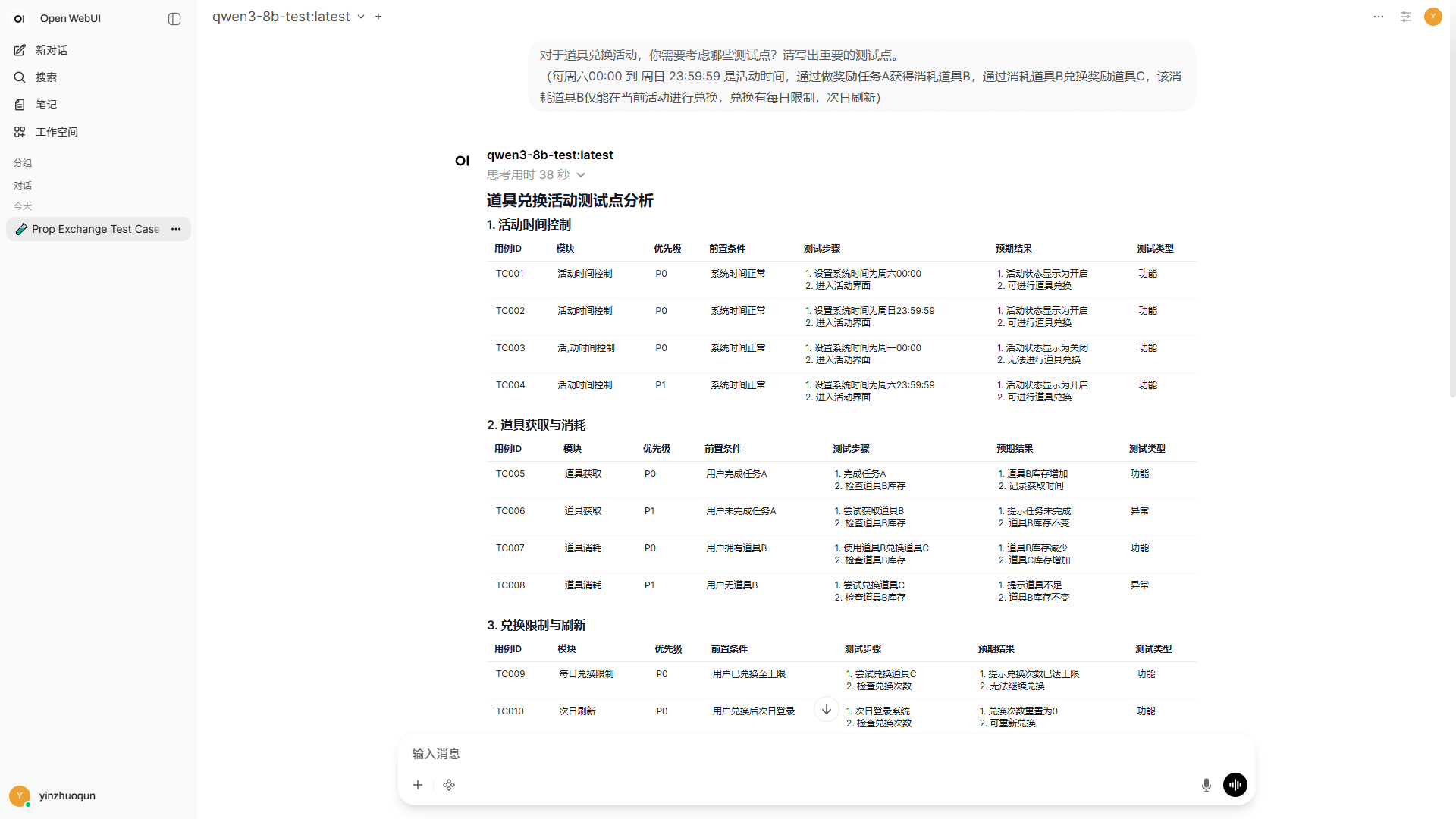
web 化体验 ollama 本地模型 qwen3:8b
要自己搭建起来一样哦

本作品由 卓越笔记 采用 知识共享署名 - 非商业性使用 - 相同方式共享 4.0 国际许可协议 进行许可
前一篇: dify Too many incorrect password attempts. Please try again later. dify 账号输入密码次数多了被锁如何解决
下一篇: 一文了解 AI 大模型的 LLM、prompt、RAG、MCP、Agent、Skill、Rule、dify、ollama、open-webui、LangChain、OpenClaw、qoder、CodeBuddy 、trae、cursor 等
关于作者
Zhuoyuebiji ( 广东·深圳 )
🚩成长的时候,能帮有需要的你
我是 卓越笔记,软件测试工作者,热爱互联网,喜欢琢磨,遇到问题就一定要找到答案。我的博客主要记录学习中遇到的知识点和遇到的问题及问题的解决方法。欢迎同样热爱互联网的小伙伴们交换友链,一起探索互联网的世界 😊