抽奖日志表统计中奖的次数和奖品出现的概率
抽奖日志表结构
-- game.smelt_log definition
CREATE TABLE `smelt_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL DEFAULT '0' COMMENT 'user_id',
`create_date` int NOT NULL DEFAULT '0' COMMENT '日期',
`prize_id` int NOT NULL DEFAULT '0' COMMENT '发放道具id',
`prize_type` int NOT NULL DEFAULT '0' COMMENT '奖励道具类型',
`prize_num` decimal(22,12) NOT NULL DEFAULT '0.000000000000' COMMENT '获得奖励数量',
`cost_slag_rock` decimal(22,12) NOT NULL DEFAULT '0.000000000000' COMMENT '消耗道具1',
`cost_slag_ore` decimal(22,12) NOT NULL DEFAULT '0.000000000000' COMMENT '消耗道具2',
`cost_slag_diamond` decimal(22,12) NOT NULL DEFAULT '0.000000000000' COMMENT '消耗道具3',
`cost_slag_rune` decimal(22,12) NOT NULL DEFAULT '0.000000000000' COMMENT '消耗道具4',
`state` tinyint NOT NULL DEFAULT '0' COMMENT '0:未完成 1:已完成',
`sync_id` bigint NOT NULL DEFAULT '0' COMMENT '跨库id',
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=97521 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='抽奖记录';
mysql < 8.0 查询法
子查询(兼容所有 MySQL 版本,推荐新手)来实现,先通过子查询统计每个 prize_id 的次数,再关联计算总次数和比例,兼容性最好。
-- 最终版:统计次数 + 占比(保留两位小数更易读)
SELECT
t.prize_id,
t.prize_count,
-- 计算占比,ROUND 保留两位小数,*100 转为百分比(可选)
ROUND(t.prize_count / total.total_count, 4) * 100 AS prize_ratio
FROM (
-- 子查询1:统计每个 prize_id 的出现次数
SELECT
prize_id,
COUNT(prize_id) AS prize_count
FROM game.melt_log AS lsl
WHERE lsl.id > 70000
GROUP BY lsl.prize_id
) AS t,
(
-- 子查询2:统计符合条件的总记录数(所有 prize_id 的次数之和)
SELECT COUNT(prize_id) AS total_count
FROM game.smelt_log AS lsl
WHERE lsl.id > 70000
) AS total
-- 按次数降序排列
ORDER BY t.prize_count DESC;
Mysql >= 8.0 查询法
窗口函数(MySQL 8.0+ 可用,更简洁),使用窗口函数 SUM() OVER () 直接计算总次数,代码更精简。
SELECT
prize_id,
COUNT(prize_id) AS prize_count,
-- 窗口函数 SUM(COUNT(prize_id)) OVER () 得到总次数,计算占比
ROUND(COUNT(prize_id) / SUM(COUNT(prize_id)) OVER (), 4) * 100 AS prize_ratio
FROM game.smelt_log AS lsl
WHERE lsl.id > 70000
GROUP BY lsl.prize_id
ORDER BY prize_count DESC;
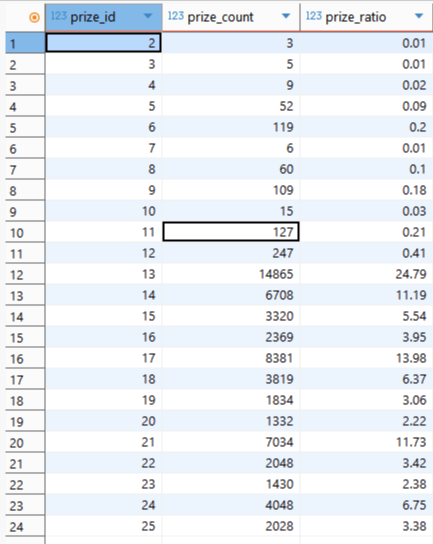
sql 查询结果
日志设计的合适,测试省事不少。
测试方法
-
单用户跑接口并发(同步)
-
多用户跑接口并发(单次、多次)
测试结果记录
测试概率,非正式上线概率。
| 奖品ID | 奖品名称 | 品阶 | 数量 | 概率 | 分奖数值验证 | 用户账户到账和 奖池扣减数值验证 |
道具概率验证 |
窗口函数(拓展)
窗口函数的本质是:在保留原有分组 / 行结构的前提下,计算 “指定范围” 的聚合值(比如总和、平均值),和 GROUP BY 那种 “分组后只保留分组结果” 完全不同。
分步拆解 SUM(COUNT(prize_id)) OVER ()
第一步:内层 COUNT(prize_id) —— 先算每个分组的次数
-
这里
COUNT(prize_id)的作用就是算出每个 prize_id 自己的出现次数。SELECT prize_id, COUNT(prize_id) AS prize_count FROM game.smelt_log AS lsl WHERE lsl.id > 70000 GROUP BY prize_id; -
假设这个查询的结果是这样的(模拟数据):
| prize_id | prize_count |
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
第二步:外层 SUM(...) OVER () —— 算所有分组的总次数
-
OVER ()是窗口函数的核心,括号里为空表示 “把整个查询结果集作为一个‘窗口’(范围)”。所以
SUM(COUNT(prize_id)) OVER ()的逻辑是:-
先拿到第一步每个分组的
COUNT(prize_id)结果(100、200、300); -
然后
SUM(...)把这些结果全部加起来,得到总次数(100+200+300=600); -
关键:这个总次数(600)会附加到每一行,而不是像
GROUP BY那样只返回一个总和。
-
第三步:组合起来 —— 每行都能拿到 “自己的次数” 和 “全局总次数”
把两步结合,完整的窗口函数查询执行后,中间结果其实是这样的(模拟):
| prize_id | COUNT(prize_id) | SUM(COUNT(prize_id)) OVER () |
| 1 | 100 | 600 |
| 2 | 200 | 600 |
| 3 | 300 | 600 |
你看,每一行都同时有 “自己的次数” 和 “所有分组的总次数”,这时候用 COUNT(prize_id) / SUM(COUNT(prize_id)) OVER () 就能算出每一行的占比:
-
prize_id=1:100/600 ≈ 16.67%
-
prize_id=2:200/600 ≈ 33.33%
-
prize_id=3:300/600 = 50%
日志表抽奖记录是 json 格式(拓展)
统计概率
使用 python 取数据,自行统计数据
数据校验
-
积分/道具增减值
-
积分(用户/池子)扣减和到账

文章部分资料可能来源于网络,如有侵权请告知删除。谢谢!
前一篇: 全力推进和落地 AI QA 工作流
下一篇: 测试任务提测标准和流程
关于作者
Zhuoyuebiji ( 广东·深圳 )
🚩成长的时候,能帮有需要的你
我是 卓越笔记,软件测试工作者,热爱互联网,喜欢琢磨,遇到问题就一定要找到答案。我的博客主要记录学习中遇到的知识点和遇到的问题及问题的解决方法。欢迎同样热爱互联网的小伙伴们交换友链,一起探索互联网的世界 😊