django-haystack 让检索结果开头不缩略显示(完全显示)
用 haystack 做检索,检索的关键词前面被缩略显示了即显示 "...",有时候会造成一些麻烦。
自己做了一些改动后,取消了部分缩略显示不合理的地方,效果如下:
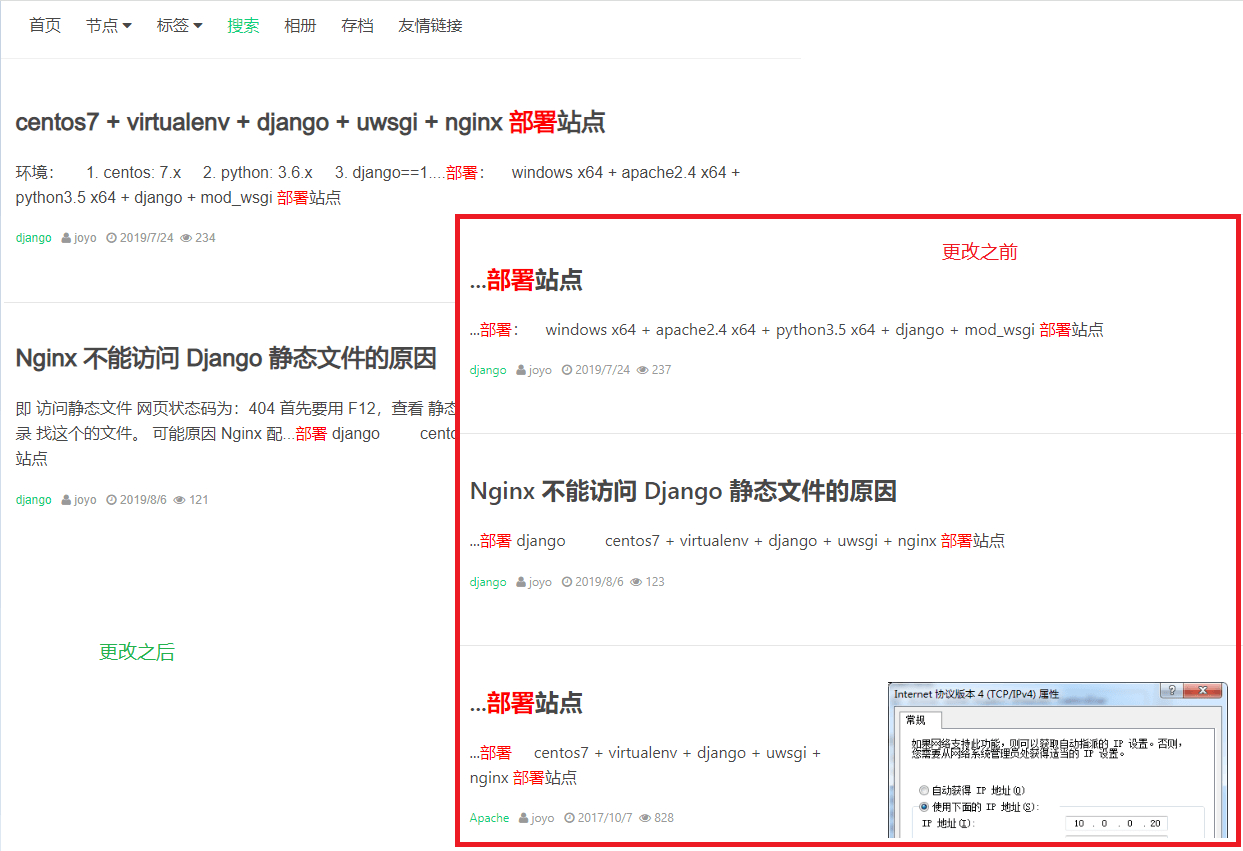
如何配置 haystack 检索请看:django-haystack 全文检索
不缩略显示的修改方法
1. 修改 joyoo\blog\templatetags\highlighting.py
# encoding: utf-8
from __future__ import absolute_import, division, print_function, unicode_literals
from django.utils.html import strip_tags
class Highlighter(object):
css_class = 'highlighted'
html_tag = 'span'
max_length = 200
text_block = ''
def __init__(self, query, **kwargs):
self.query = query
if 'max_length' in kwargs:
self.max_length = int(kwargs['max_length'])
if 'html_tag' in kwargs:
self.html_tag = kwargs['html_tag']
if 'css_class' in kwargs:
self.css_class = kwargs['css_class']
self.query_words = set([word.lower() for word in self.query.split() if not word.startswith('-')])
def highlight(self, text_block):
self.text_block = strip_tags(text_block)
highlight_locations = self.find_highlightable_words()
# print(highlight_locations)
# 检索结果不缩略显示 - 此处有修改,增加一个返回值 text_pre
text_pre = ""
for key, values in highlight_locations.items():
# print(key, values)
if values:
if values[0] > 100:
text_pre = self.text_block[0: 100] + "..."
else:
text_pre = self.text_block[0: values[0]]
start_offset, end_offset = self.find_window(highlight_locations)
return self.render_html(highlight_locations, start_offset, end_offset, text_pre)
# return self.render_html(highlight_locations, start_offset, end_offset)
def find_highlightable_words(self):
# Use a set so we only do this once per unique word.
word_positions = {}
# Pre-compute the length.
end_offset = len(self.text_block)
lower_text_block = self.text_block.lower()
for word in self.query_words:
if not word in word_positions:
word_positions[word] = []
start_offset = 0
while start_offset < end_offset:
next_offset = lower_text_block.find(word, start_offset, end_offset)
# If we get a -1 out of find, it wasn't found. Bomb out and
# start the next word.
if next_offset == -1:
break
word_positions[word].append(next_offset)
start_offset = next_offset + len(word)
return word_positions
def find_window(self, highlight_locations):
best_start = 0
best_end = self.max_length
# First, make sure we have words.
if not len(highlight_locations):
return (best_start, best_end)
words_found = []
# Next, make sure we found any words at all.
for word, offset_list in highlight_locations.items():
if len(offset_list):
# Add all of the locations to the list.
words_found.extend(offset_list)
if not len(words_found):
return (best_start, best_end)
if len(words_found) == 1:
return (words_found[0], words_found[0] + self.max_length)
# Sort the list so it's in ascending order.
words_found = sorted(words_found)
# We now have a denormalized list of all positions were a word was
# found. We'll iterate through and find the densest window we can by
# counting the number of found offsets (-1 to fit in the window).
highest_density = 0
if words_found[:-1][0] > self.max_length:
best_start = words_found[:-1][0]
best_end = best_start + self.max_length
for count, start in enumerate(words_found[:-1]):
current_density = 1
for end in words_found[count + 1:]:
if end - start < self.max_length:
current_density += 1
else:
current_density = 0
# Only replace if we have a bigger (not equal density) so we
# give deference to windows earlier in the document.
if current_density > highest_density:
best_start = start
best_end = start + self.max_length
highest_density = current_density
return (best_start, best_end)
def render_html(self, highlight_locations=None, start_offset=None, end_offset=None, text_pre=None):
# def render_html(self, highlight_locations=None, start_offset=None, end_offset=None):
# Start by chopping the block down to the proper window.
text = self.text_block[start_offset:end_offset]
# Invert highlight_locations to a location -> term list
term_list = []
for term, locations in highlight_locations.items():
term_list += [(loc - start_offset, term) for loc in locations]
loc_to_term = sorted(term_list)
# Prepare the highlight template
if self.css_class:
hl_start = '<%s class="%s">' % (self.html_tag, self.css_class)
else:
hl_start = '<%s>' % (self.html_tag)
hl_end = '</%s>' % self.html_tag
# Copy the part from the start of the string to the first match,
# and there replace the match with a highlighted version.
highlighted_chunk = ""
matched_so_far = 0
prev = 0
prev_str = ""
for cur, cur_str in loc_to_term:
# This can be in a different case than cur_str
actual_term = text[cur:cur + len(cur_str)]
# Handle incorrect highlight_locations by first checking for the term
if actual_term.lower() == cur_str:
if cur < prev + len(prev_str):
continue
highlighted_chunk += text[prev + len(prev_str):cur] + hl_start + actual_term + hl_end
prev = cur
prev_str = cur_str
# Keep track of how far we've copied so far, for the last step
matched_so_far = cur + len(actual_term)
# Don't forget the chunk after the last term
highlighted_chunk += text[matched_so_far:]
# 检索结果不缩略显示 - 此处有修改, highlighted_chunk 加上关键词前面的内容
if start_offset > 0:
# highlighted_chunk = '...%s' % highlighted_chunk
highlighted_chunk = '%s%s' % (text_pre, highlighted_chunk)
if end_offset < len(self.text_block):
highlighted_chunk = '%s...' % highlighted_chunk
return highlighted_chunk
2. 在 settings.py 配置 haystack 使用自定义高亮函数:
# Handle a user-defined highlighting function. 处理用户定义的突出显示函数。
HAYSTACK_CUSTOM_HIGHLIGHTER = "blog.templatetags.highlighting.Highlighter"
^_^

本作品由 卓越笔记 采用 知识共享署名 - 非商业性使用 - 相同方式共享 4.0 国际许可协议 进行许可
前一篇: django Foreignkey 之 on_delete
下一篇: django runserver: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 0: invalid start byte
关于作者
Zhuoyuebiji ( 广东·深圳 )
🚩成长的时候,能帮有需要的你
我是 卓越笔记,软件测试工作者,热爱互联网,喜欢琢磨,遇到问题就一定要找到答案。我的博客主要记录学习中遇到的知识点和遇到的问题及问题的解决方法。欢迎同样热爱互联网的小伙伴们交换友链,一起探索互联网的世界 😊