评论接入百度云 文本审核 API
官方地址
https://cloud.baidu.com/doc/ANTIPORN/s/pjwvypelq
接口文档下载
下载文档(更新时间:2019-11-14)
KEY 申请入口
https://console.bce.baidu.com/ai/?fromai=1#/ai/antiporn/overview/index (申请一个 APP)
接口描述
运用业界领先的深度学习技术,判断一段文本内容是否符合网络发文规范,实现自动化、智能化的文本审核。审核内容分为6大类型:色情文本、政治敏感、恶意推广、网络暴恐、低俗辱骂、低质灌水。 定制功能可支持在百度云控制台自由选择审核类型(一个或多个),支持自定义配置文本审核黑名单,且可通过调整阈值控制审核的松紧度标准,大幅度满足文本审核的个性化需求。
接口限制(免费版)
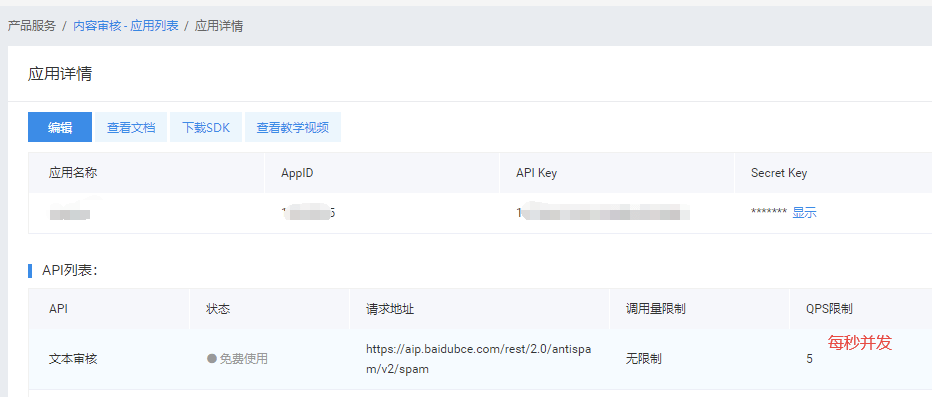
接口使用
1. 先安装 baidu-aip
pip install baidu-aip
2. 我的代码
# baidu_check.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: yinzhuoqun
@site: http://zhuoqun.info/
@email: yin@zhuoqun.info
@time: 2019/11/20 1:21 AM
"""
from aip import AipImageCensor
from utils.json_to_object import json_to_object
BAIDU_APP_ID = '填自己申请的'
BAIDU_API_KEY = '填自己申请的'
BAIDU_SECRET_KEY = '填自己申请的'
labels_text = {
1: "暴恐违禁",
2: "色情内容",
3: "政治敏感",
4: "恶意推广",
5: "低俗辱骂",
6: "低质灌水"
}
spam_text = {
0: "不违禁",
1: "违禁",
2: "人工复审"
}
class CheckText:
def __init__(self, text):
self.text = text
self.app_id = BAIDU_APP_ID
self.api_key = BAIDU_API_KEY
self.secret_key = BAIDU_SECRET_KEY
self.client = AipImageCensor(self.app_id, self.api_key, self.secret_key)
def request_api(self):
# print(self.text)
return self.client.antiSpam(self.text)
def response(self):
res = self.request_api()
if "error_msg" in res.keys():
return {"status": 203, "msg": res["error_msg"]}
else:
check_status = res["result"]["spam"]
if check_status == 0:
return {"status": 201, "msg": "审核通过"}
elif check_status == 1:
labels = res["result"]["reject"]
labels_id = [(review["label"]) for review in labels]
reason = ",".join([labels_text[label_id] for label_id in labels_id]).strip(",")
# print(reason)
return {"status": 403, "msg": "审核不通过", "reason": reason}
elif check_status == 2:
labels = res["result"]["review"]
labels_id = [(review["label"]) for review in labels]
reason = ",".join([labels_text[label_id] for label_id in labels_id]).strip(",")
# print(reason)
return {"status": 403, "msg": "人工复审", "reason": reason}
else:
return {"status": 200, "msg": "人工复审", "reason": "百度异常"}
def response_format(self):
return json_to_object(self.response())
if __name__ == "__main__":
text = "今晚弹药枪支吗傻x"
# text = "傻x"
c = CheckText(text)
print(c.response_format())
# json_to_object.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: yinzhuoqun
@site: http://zhuoqun.info/
@email: yin@zhuoqun.info
@time: 2019/11/20 12:02 AM
"""
from argparse import Namespace
import json
def json_to_object(data):
"""
json 或 字典 转成 object
:param data:
:return:
"""
if isinstance(data, dict):
return json.loads(json.dumps(data), object_hook=lambda d: Namespace(**d))
else:
return json.loads(data, object_hook=lambda d: Namespace(**d))
Django 中去掉 HTML 标签
>>> from django.utils.html import strip_tags
>>>
>>> html = "<a>xieboke.net</a>"
>>> strip_tags(html)
'xieboke.net'
>>>
^_^

文章部分资料可能来源于网络,如有侵权请告知删除。谢谢!
前一篇: Django 使用 celery 执行异步任务和定时任务
下一篇: 站点 robots 文件在线生成
公告







关于作者
Zhuoyuebiji ( 广东·深圳 )
🚩成长的时候,能帮有需要的你
我是 卓越笔记,软件测试工作者,热爱互联网,喜欢琢磨,遇到问题就一定要找到答案。我的博客主要记录学习中遇到的知识点和遇到的问题及问题的解决方法。欢迎同样热爱互联网的小伙伴们交换友链,一起探索互联网的世界 😊